PodEngine
The world's most advanced podcast search engine & intelligence platform.
6-figure ARR · Multiple enterprise API clients · VC-backed
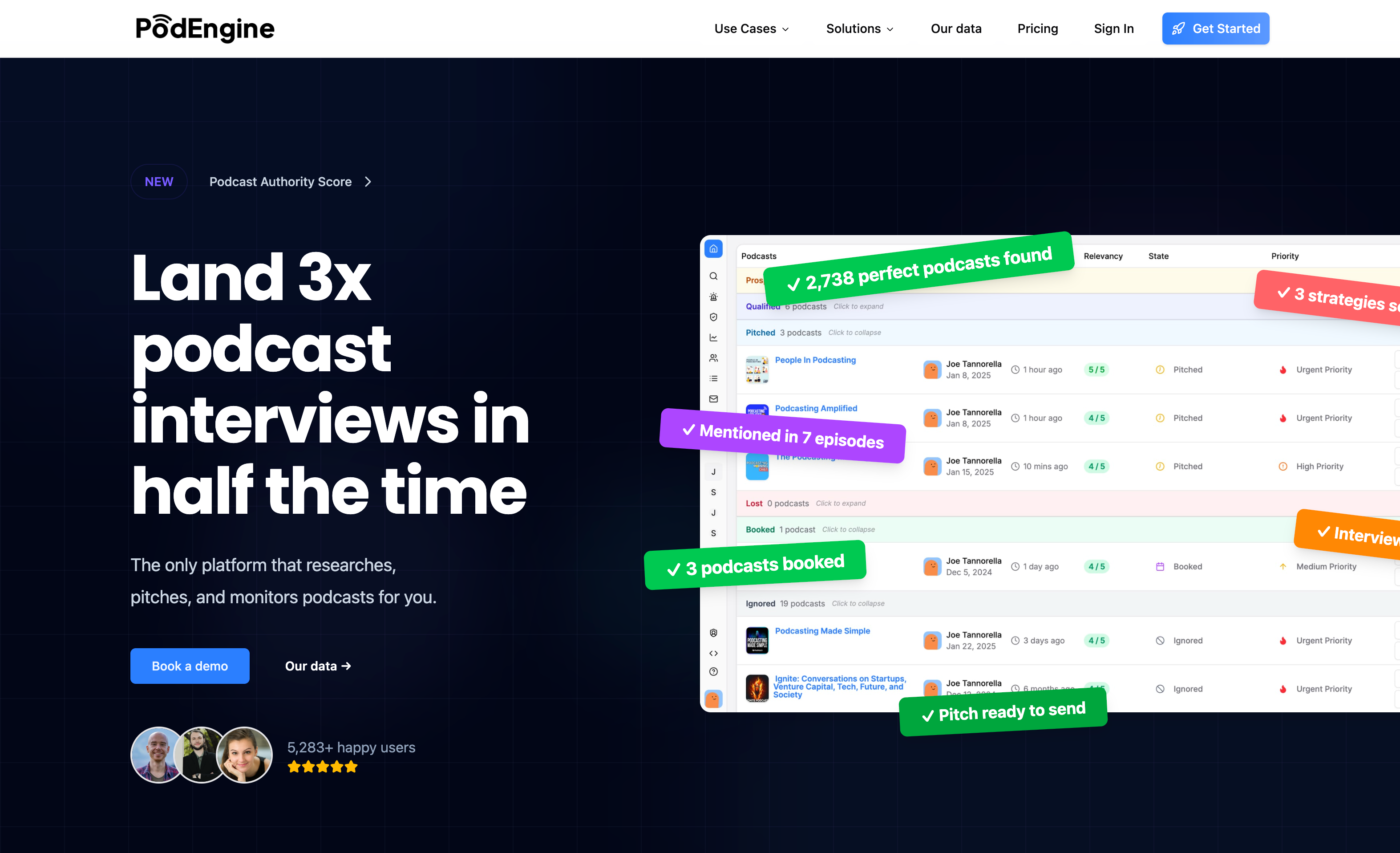
AI-powered podcast intelligence platform processing 6M+ episodes with 50+ specialized LLM prompts to automate guest booking research. Used by leading agencies including Interview Valet, Earworm, and Podcast Ally.
Scale
- 6,000,000+ episodes indexed
- 50,000+ podcasts tracked
- 12+ integrated data sources
- 6-shard distributed Elasticsearch cluster
- 3 LLM providers (Anthropic, Gemini, OpenAI) + 6 Whisper variants
Core Capabilities
Intelligent Podcast Discovery — Multi-strategy relevancy scoring matches guests to podcasts using context-aware prompts. 1-5 rating scale with justification, strengths, and concerns for each match.
Guest Prep Document Generation — 6-stage LLM pipeline analyzes 10+ episode transcripts to produce personalized briefing docs: host background, recurring bits, likely questions by category, and topics to steer toward or avoid.
Deep Episode Analysis — 11+ LLM prompts extract podcast affiliation, genres, host identification, sponsor detection, political bias scoring, target demographics, and content themes from every transcript.
Data Enrichment — Automated collection of contact emails, 20-platform social media detection, YouTube channel matching with confidence scoring, and cross-platform directory IDs (Apple, Spotify, Castbox, Podchaser).
Enterprise API — Production-grade API powering some of the world’s biggest companies. Full programmatic access to podcast data, transcripts, and AI analysis for custom integrations and workflows.
Results
- 10+ hours saved per project via automated discovery
- 5x higher response rates from personalized, validated outreach
- 75% reduction in manual research time
- Personalized prep improves interview performance
Architecture
- LLM evaluation framework for A/B testing models and prompts to maximize output quality
- Multi-provider LLM with per-prompt model selection and cost tracking
- Message-driven processing via RabbitMQ with 5-level priority queues
- Denormalized design for high-write concurrency on processing status
- 24-hour TTL caching on generated documents